
OpenAI 联合创始人、研究科学家 John Schulman 认为,RLHF 才是 ChatGPT 的秘密武器(secret sauce)。训练数据的体量固然重要,但是让 ChatGPT 更容易推断出用户的意图,产生质变的根本原因是已在 InstructGPT(ChatGPT 前身)使用的 “人类反馈的强化学习(RLHF)” 技术。
Google…
IT技术
(
twitter.com
)
OpenAI 联合创始人、研究科学家 John Schulman 认为,RLHF 才是 ChatGPT 的秘密武器(secret sauce)。训练数据的体量固然重要,但是让 ChatGPT 更容易推断出用户的意图,产生质变的根本原因是已在 InstructGPT(ChatGPT 前身)使用的 “人类反馈的强化学习(RLHF)” 技术。
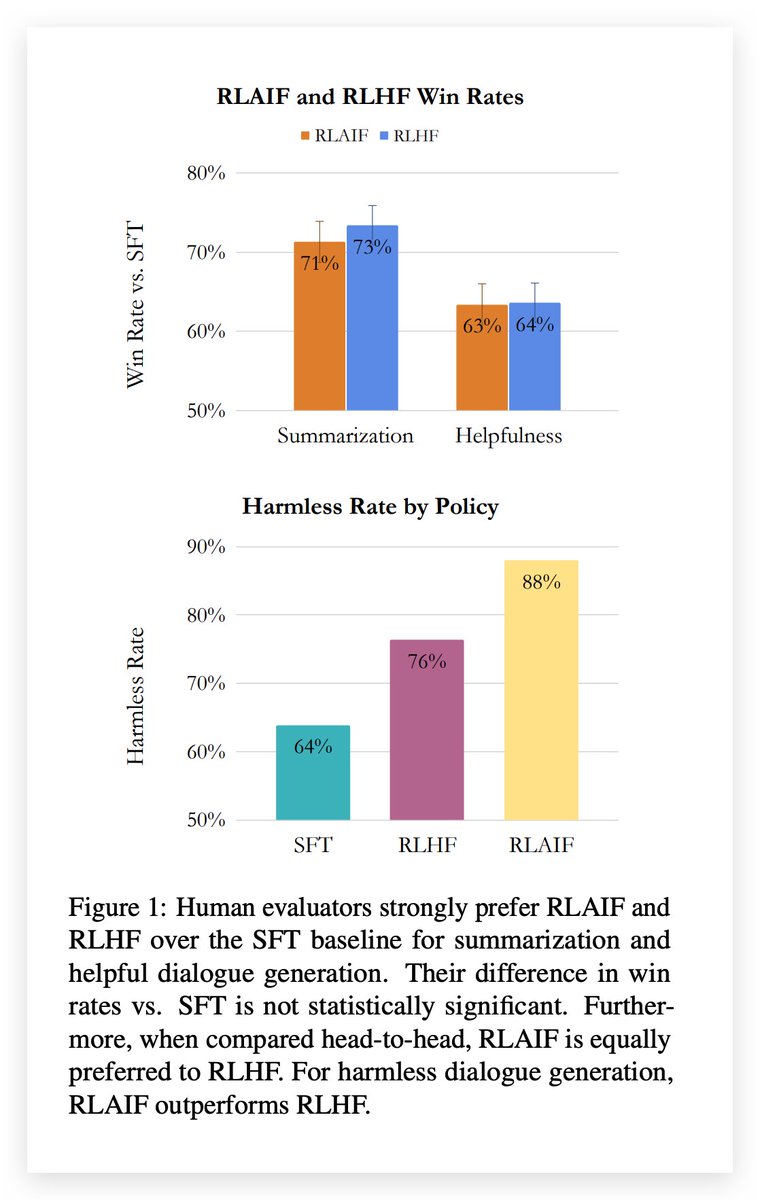
Google 最近写了一篇论文《RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback》,https://t.co/vOIe86f6BP,提出了使用 AI Feedback (RLAIF) 来进行强化学习,根据人类评估者的评价,在摘要、有帮助的对话生成和无害对话生成等任务中,RLAIF 取得了与 RLHF 相当或更好的性能。
结合 OpenAI Q*(Q-Star)项目的爆料,“AI 具备了自主学习和自我改进的能力,模型可进行自主决策,并且可能已具备轻微自我意识”,有研究者猜测与强化学习中的 Q-learning 算法相关。这个方向的最新资料值得跟踪学习下。
奖励模型是强化学习中的重要组成部分,OpenAI 训练中涉及到这一块的公开内容是比较少的,《The History and Risks of Reinforcement Learning and Human Feedback》,https://t.co/Em9UJI2k0J,这篇论文强调了奖励模型缺乏透明度和严格评估,并呼吁在该领域进行更全面的研究和透明度。
奖励模型的设计直接影响了 AI 与用户进行正常交流时所表现出的道德判断、价值观念和偏见,如果 AI 具备了轻微的自我意识,那么这部分内容的公开透明在未来也会变得更加重要。
点击图片查看原图
