2
1
0

一个开源的多模态 LLM Unified-IO 2。
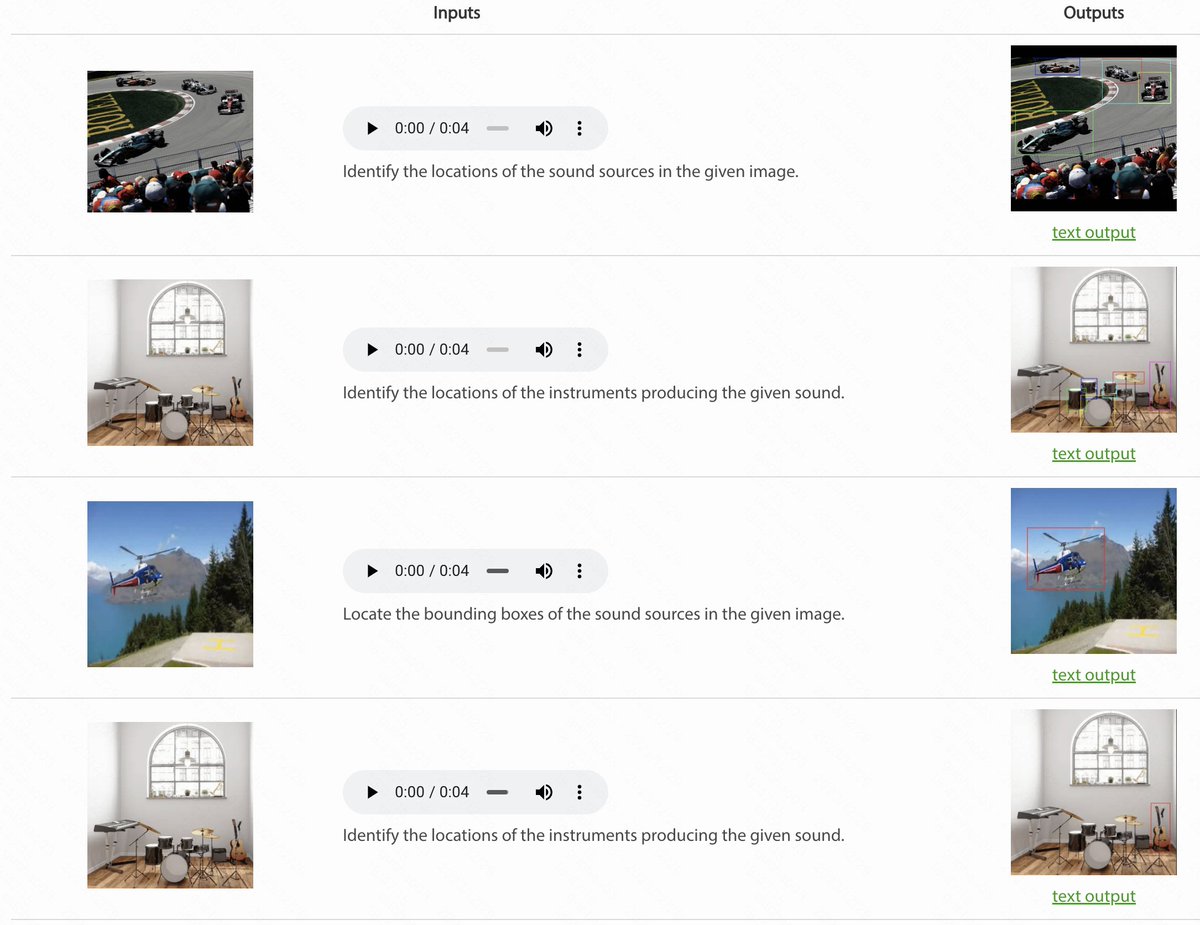
比较离谱的是它可以实现语音理解和动作理解还有图像标记这种任务,还可以理解空间关系。真正的 All in one 。
甚至还可以驱动机器人做对应的操作。
项目简介:
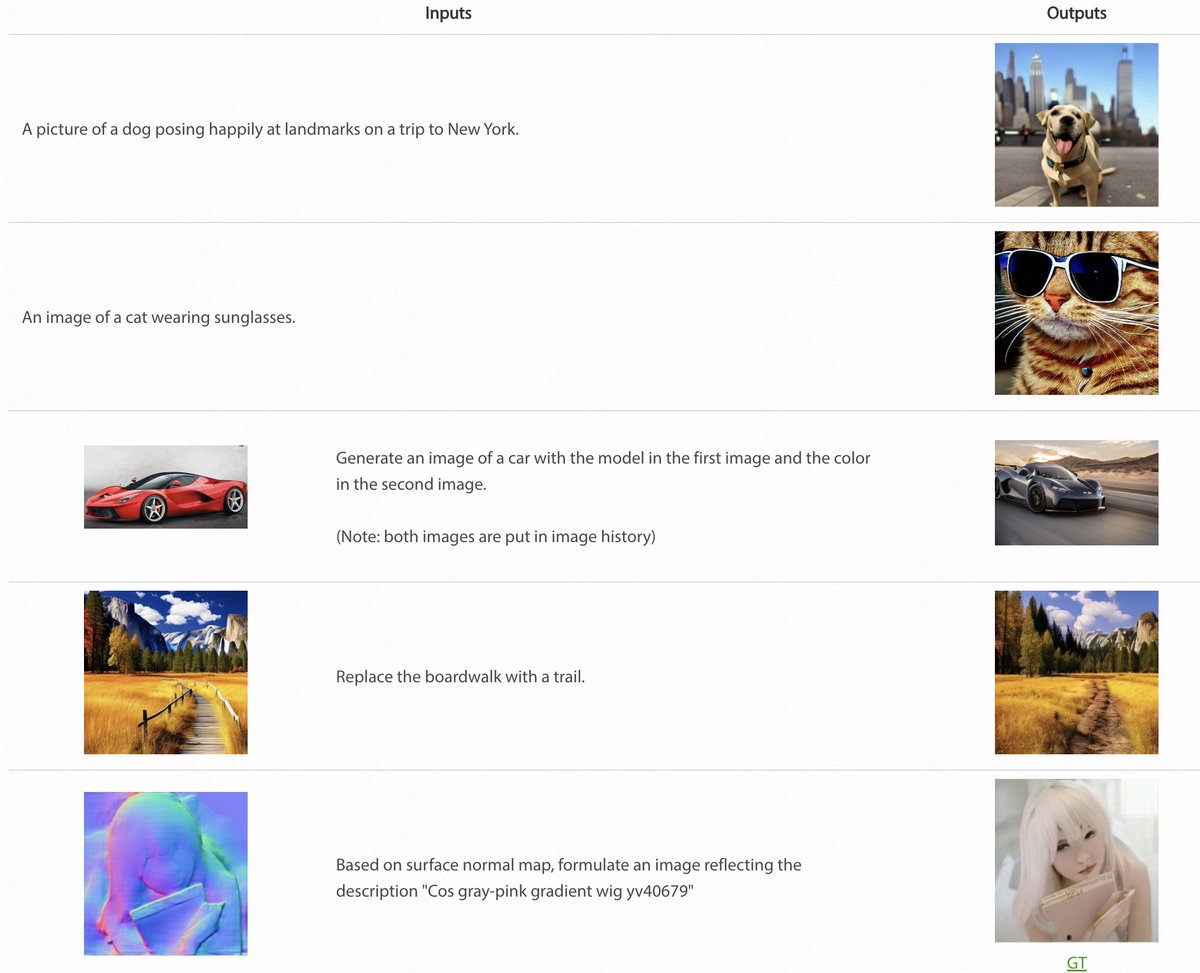
Unified-IO 2,这是第一个能够理解和生成图像、文本、音频和动作的自回归多模态模型。…
IT技术
(
twitter.com
)
由
歸藏
提交
一个开源的多模态 LLM Unified-IO 2。
比较离谱的是它可以实现语音理解和动作理解还有图像标记这种任务,还可以理解空间关系。真正的 All in one 。
甚至还可以驱动机器人做对应的操作。
项目简介:
Unified-IO 2,这是第一个能够理解和生成图像、文本、音频和动作的自回归多模态模型。
为了统一不同的模态,我们将输入和输出(图像、文本、音频、动作、框等)进行分词,并将它们置于一个共享的语义空间中,然后使用单个编码器-解码器变换器模型进行处理。由于使用多样的模态进行训练非常困难,我们提出了各种架构改进来稳定模型。
我们从头开始在来自不同来源的大型多模态预训练语料库上训练我们的模型,并采用多模态混合去噪目标。为了学习一系列广泛的技能,比如遵循多模态指令,我们构建并微调了一个包含120个现有数据集的集合,并进行了提示和增强。
通过一个统一的模型,Unified-IO 2在GRIT基准测试中达到了最先进的性能,并在30多个基准测试中取得了强大的结果,包括图像生成和理解、文本理解、视频和音频理解以及机器人操作。我们将所有的模型都发布给研究界。
项目地址:https://t.co/zf9hzLJltK
点击图片查看原图

点击图片查看原图
点击图片查看原图

点击图片查看原图
Markdown支持
评论加载中...
您可能感兴趣的:
更多
2
2
1
1
3
2
1
1
4
2
1
1
5
2
1
1
6
2
1
1
7
1
0
0
8
2
1
1
